With this post I'm kicking off a series designed to help analysts reverse engineer undocumented - or poorly documented - network protocols. It is fairly common for incident responders to be presented with a network packet capture (PCAP) containing undocumented bi-directional traffic, or binary files exhibiting such behavior. The content and purpose of these transactions is often learned through "conventional" reverse engineering of the client binary executable (using common dynamic and static techniques). This process is time-consuming in the context of rapidly-evolving incident response scenarios, as extensive analysis of network communications may be complicated by a number of factors. I have been in a number of situations where the binary file simply isn't available for analysis, or the lack of access to the corresponding server code presents an unreasonably large road block. Focused analysis of an unknown network protocol can be accelerated to better support incident response detection needs using a number of complementary techniques, leveraging multiple sources of information, through the process of Protocol Reverse Engineering (PRE).
Understand that the perspective I provide herein is designed to be just one way to approach PRE; it's a pseudo-formal survey of the tools, techniques, and methodologies that I've experienced or observed to be effective that is deliberately proscriptive, rather than prescriptive. It is not an exhaustive study, and only designed to cover common needs of analysts - particularly engaged in incident response (or as some of us call it, Computer Network Defense / CND). I will gloss over techniques commonly covered by conventional RE training like FOR 610, and refer you to one of the frequently-offered courses such as the one I'm teaching in Baltimore in early August (you can suffer one shameless plug, right?).
Introduction to PRE
There are a few definitions of PRE floating around. I'm particularly fond of a paraphrase of the definition used by UC Berkley's BitBlaze project: PRE is the process of extracting the structure, attributes, and data from a network protocol implementation without access to its specification, or in other words, access to formal semantic documentation of the protocol specification is not possible.
PRE accomplishes this by combining different pieces of data collected from incident response to discover attributes of the unknown protocol which can then be turned into functional detections to improve computer network defense (CND) and security intelligence analysis. This approach is illustrated in the figure below.
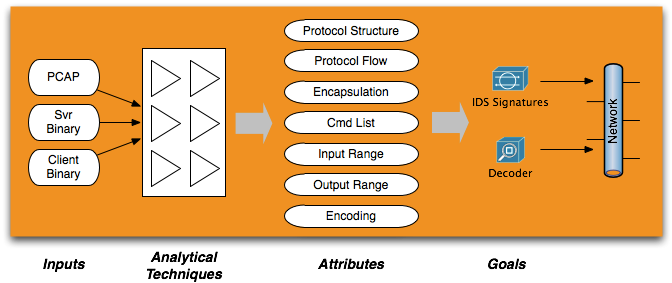
Goals
For the purposes of Computer Network Defense (CND) and incident response, the protocol's specification is most commonly used to support two goals: the construction of network signatures and protocol decoders. Protocol decoders can be a forensic gold mine if packet captures are available to analysts, but often this is not the case: organizations rarely appreciate the intelligence provided by protocol decoders and often lack a platform on which to deploy them. There's a common obstacle, however, to building both signatures and decoders: the perceived enormity of the task of PRE.
Inputs
One way I distinguish PRE from conventional reverse-engineering is that it involves analysis of more than just a single binary executable. Generally, analysts will have at hand one or more of the following:
- Client binary or source code (the system receiving commands)
- Server binary or source code (the system sending commands)
- Captured network activity (i.e. PCAP)
Although having all three of these pieces of information is ideal, an analyst's objectives from PRE can often be achieved with a certain efficacy even if only one piece of the puzzle is available - even if that piece is only network activity. With respect to PCAPs, access to both the client and server permits creation of network traffic, of course, but I maintain that nothing substitutes for the real thing - as the experienced analyst knows, network activity in the lab never perfectly reflects that observed in the wild.
Protocol Attributes
Of course, what each of these components can generally provide via PRE is different, and the ease of discovery varies. The most common attributes that can be captured in a signature or decoder to uniquely identify the protocol in question are:
- Protocol structure: The layout of control signaling, metadata, and payload data for each command.
- Protocol flow: The timing, order, size, and directionality of each complete command and corresponding response.
- Encapsulation: The protocol encapsulating the subject protocol, and method of encapsulation (i.e. if the carrier protocol is above layer 4).
- Command list: The set of commands that may be issued to a client.
- Input range: The range of valid values for each possible command.
- Output range: The range of valid results from each command.
- Encoding: The means by which each protocol datagram is transformed prior to encapsulation (often for malicious C2, this is to evade detection by generic IDS signatures).
I've put together a notional chart illustrating what analysts may want to focus on for each component - the "low-hanging fruit," if you will. Green represents optimal places to learn about an attribute, olive less optimal, and no shading I generally find the most problematic source for information about an attribute. I'll add that if source code is available for either the client or server, unlocking many of the mysteries of a protocol's specification becomes dependent largely upon the analyst's ability to understand the language in which it is written.
| Attribute | PCAP | Client | Server |
| Protocol Structure | |||
| Protocol Flow | |||
| Encapsulation | |||
| Command list | |||
| Input Range | |||
| Output Range | |||
| Encoding |
Five Protocol States
The aforementioned protocol attributes may change depending on the state of the communication between the client and server. This means that detection may be very simple in one state, but far more difficult in another. Additionally, analysts may find that they want to prioritize their PRE objectives based on the most common, or most concerning, protocol state they expect to see in practice. I find it useful to group communications between client and server, and therefore the protocol, into the following five states:
- Idle
- Interactive
- Upload
- Download
- Errant
I've enumerated this list because, with the exception of the Errant state, this is typically the order in which one sees a backdoor protocol used maliciously. Most modern backdoors will be installed on a victim system (the client), and begin beaconing to the server in an Idle state. This is often periodic, containing basic environment data from the computer on which the client is operating. At some point in time, the operator will begin issuing commands to the client (directory listings, etc etc), entering the Interactive state. It's common to see the operator Upload tools to the client in order to act on his or her objectives. Finally, exfiltration will happen in the Download state. Now, of course, this is not deterministic and different actors will operate in different ways - this is a generalization.
The Errant state is important to call out because some clients will behave differently if an unexpected condition is encountered. Remember that in the case of trojan / backdoor clients, the adversary is making a number of assumptions about the executing environment. The most common error condition I see is when a trojan cannot reach the server due to some intentional or incidental access failure. Behaviors in this condition range from the client becoming extremely verbose in its retry attempts, to extended shutdown modes.
Approaching PRE
Philosophically, PRE aims to build the protocol specification which is missing. For us practitioners, that translates into the ability to decode and assign semantic meaning to all network activity a given program may generate. Many protocols in use today have a level of complexity that might make this goal seem impossibly high. If your gut tells you this is the case, you'll be happy to know science has your back: PRE can be shown to fall into a class of problems information theory calls NP-complete under certain conditions. In other words, finite-state computers like those we use today cannot efficiently reverse-engineer protocols as their complexity grows. Fortunately for us, most custom C2 protocols used by backdoors/trojans are simple - true in my experience as well as logically, since it is costly for adversaries to build an entirely new, complex protocol.
The unfortunate truth is that automated PRE is largely academic for now, and circumstances where necessary data is embedded in a complex protocol with bad or "proprietary" documentation do occur. How, then, could a mere mortal analyst possibly accomplish this task? My answer is "we don't." We let the objectives of our output determine what we get out of PRE, and when our job is finished. Again, our objectives are construction of protocol decoders and network signatures available as quickly as possible. In agreement with these objectives, it is wise to follow a few principles when performing PRE, which you will see demonstrated in some of the forthcoming articles on PRE techniques.
The Completeness Principle: Some is Enough
I put to you that partial knowledge of a protocol can be sufficient to meet some, or all, of the needs of those analyzing it. The history of information - pardon, CYBER security is rife with decisions ill-advised by their theoretical outcomes, and subsequent security failures. Concluding that the partial reconstruction of a protocol isn't valuable due to the possibility, likelihood, or even certainty, that parts of the traffic will remain opaque is to fall victim to this outdated mindset. Even the most limited pieces of data from a mysterious protocol can be valuable when analyzed en masse. Consider TCP: If I only knew one field, the destination port for instance, I'd still be able to get a lot of valuable information out of a PCAP.
Signature creation can also fall victim to this mentality. Though PRE may have only identified the role, value, nature, or range of a tiny portion of the protocol, and it may only be known accurate for a limited set of circumstances, codifying this in a signature is still valuable if it can yield hits with a manageable false positive (FP) rate. That's a nice segue...
The Correct-ness Principle: Function Over (syntactic) Form
The mantra of network IDS signatures has forever been to reduce false negatives (FNs): failures to detect, or "Type II errors" as scientists call them, are to be avoided even at the expense of increasing false positives (FPs). High FN's, as has been reasoned to me repeatedly, result in no trace of a bad/hostile event, and thus should be avoided even at the expense of high FPs. Although this sounds reasonable in theory, in practice, the difficulty of identifying true positives (TPs) in a pile of FPs can be prohibitively costly and error-prone.
The utility of a signature is not strictly dependent on its correctness. Remember that detection is a means to an end, not an end itself. If FPs generated by a "correct" signature cannot be distinguished from TPs in an affordable and maintainable manner, subsequent actions will not be performed and the correctness is meaningless. This is of course a balancing act that must be carefully orchestrated and tuned for the environment in which the product of PRE will be used.
The Spiral Principle: Recursive PRE & Detection
Analysts must let their questions about a protocol guide their reverse engineering. In practice this philosophy is often manifest in a recursive reverse engineering - detection loop. Partial protocol decoders raise questions about particular aspects of a protocol that guide reverse engineering. False positives and false negatives in signatures which inhibit detection serve as requirements for further PRE. Think of this as the software engineering "spiral" development model, with the realities of network activity turning into prioritized questions by analysts using existing decoders and signatures, which become requirements for PRE that result in incrementally-improved decoders and signatures, and so-on.
The Configuration Principle: Start With What You Know
Many protocols can exhibit a huge range of behaviors depending on how the client or server is configured. Sometimes this is as simple as a text file accompanying a binary, sometimes it's easily compiled into the code by a weaponizer (Poison Ivy comes to mind here), and sometimes it requires a source code rewrite. Just remember: ALL attributes of ALL protocols are configurable at some level. Attempting to capture all of these conditions in a signature or decoder becomes an exercise in futility at one point or another. Analysts should use their heads, and ask themselves a few questions.
- How is the protocol going to operate with the information I have in-hand?
- How will the protocol operate successfully in my environment?
- What likely assumptions is the adversary going to make, based on common sense, or other intelligence available from previous intrusion attempts in the same campaign?
- What structures in the binary do functions seem to access that will change the protocol's attributes?
Answers to these sorts of questions, and adherence to the other principles, should guide PRE to fast and effective detection and decoding.
Up Next...
In my next installment, I will give an overview of analytical techniques that map to different protocol attributes, given various combinations of inputs to PRE. In that entry, you can look forward to strategies for when to use methods such as:
- Encoding discovery
- Bitmasking
- Manual structure identification
- PCAP construction
- Static & Dynamic analysis
- ...and likely more
From there, we will delve in turn into some of the more obscure techniques not ordinarily covered in reverse engineering courses.
Michael is the Chief Research Analyst for Lockheed Martin's Computer Incident Response Team. He has lectured for various audiences including SANS, IEEE, the annual DC3 CyberCrime Convention, and is a co-author of a set of widely adopted techniques for intelligence-based Computer Network Defense. His current work consists of security intelligence analysis and development of new tools and techniques for incident response. Michael holds a BS in computer engineering, an MS in computer science, is working towards a PhD in systems engineering, has earned GCIA (#592) and GCFA (#711) gold certifications alongside various others, and is a professional member of ACM and IEEE.




