SEC595: Applied Data Science and AI/Machine Learning for Cybersecurity Professionals
SEC595Cyber Defense, Artificial Intelligence


Daunting as it may seem, one of the most wonderful aspects of Windows forensics is its complexity. One of the fascinating aspects of digital forensics is how we often leverage conventional operating system features to provide information peripheral to their original design. One such feature is the Windows NTFS Index Attribute, also known as the $I30 file. Knowing how to parse $I30 attributes provides a fantastic means to identify deleted files, including those that have been wiped or overwritten.
Many popular file systems such as FAT and Unix store directory information as a simple flat file. Recognizing efficiency issues with lookups within large flat files, NTFS employed B-tree indexing for several of its building blocks, providing efficient storage of large data sets and very fast lookups. As forensic examiners, we can take advantage of the NTFS B-tree implementation as another source to identify files that once existed in a given directory.
Similar to Master File Table (MFT) entries in NTFS, index entries within the B-tree are not completely removed when file deletion occurs. Instead, they are marked as deleted using a corresponding $BITMAP attribute. Additionally, the size of index nodes can vary, particularly for large filenames, providing a type of slack that can hold previously existing filenames. Since B-tree nodes are regularly shuffled to keep the tree balanced, file name remnants are scattered and it is a common occurrence to find duplicate nodes referencing the same file. Of course, the flip side of re-balancing a B-tree is that it often results in data within unallocated nodes being overwritten. Thus while we commonly find evidence of long lost files within $I30 attributes, there is no guarantee they will be present.
Interestingly, NTFS directory index entries utilize a $FILE_NAME attribute type to store file information within the index. You may recall that this is the same attribute employed by the MFT and hence it provides a treasure trove of information about the file:
A key distinction when reviewing timestamps stored within $I30 files is that these timestamps are $FILE_NAME attribute timestamps and not $STANDARD_INFORMATION timestamps that we regularly view in Windows Explorer, your favorite GUI forensics tool, and within timelines. This distinction deserves a blog post of its own, but suffice to say $FILE_NAME times are often updated in a much different (and even more arbitrary) set of circumstances. Fortunately, for $I30 files, I have observed that this set of timestamps tends to mirror those that are in $STANDARD_INFORMATION. Thus even if the original file no longer exists, we may still be able to identify its name, file size, and original timestamps!
A few examples can better illustrate how useful these entries can be. I recently had a case where it appeared a large number of files were moved to the Recycle Bin, which was subsequently emptied and most of the corresponding INFO2 file was reallocated. The $I30 file still contained information on many of those files (albeit renamed according to the Recycle Bin schema). By analyzing the MFT Change Times of the $I30 index entries, I was able to determine when the user placed each file within the Recycle Bin, and collect a list of what types of files were "recycled" using their file extensions.
In a malware or intrusion case, $I30 entries provide knowledge of a file's existence and a separate and distinct set of timestamps to compare against for signs of tampering. This is a great example of why it is extremely difficult for malware or an anti-forensics tool to reliably change all of the corresponding timestamps within a file system.
Evidence may still be found in Index Attributes even if wiping or anti-forensics software has been employed. Figure 1 shows the parsed output for a $I30 file from the Windows directory. Two deleted index entries have been highlighted. In this example, a file named fgdump.exe was overwritten using a software tool named BCWipe. The original filename was overwritten with random characters (sqhyoeop.roy) and the Modified, Accessed, and Created time stamps were set to fictitious values. Since MFT Change Times cannot be directly modified via the Windows API, that timestamp still accurately reflects when the wipe occurred. Of course the interesting part of this example is that evidence of both the original file and the wiping artifacts are contained in the slack of the $I30 file.
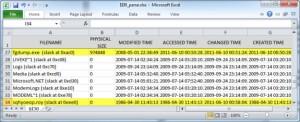
Figure 1: Evidence Found in $I30 of Use of File Wiping Software
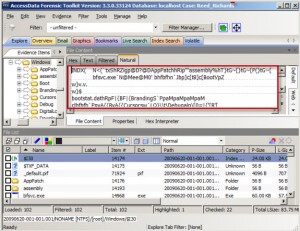
One of the primary reasons many examiners don't utilize index attribute files is because getting access to them is not always intuitive. I congratulate Access Data and their Forensic Toolkit (FTK) for clearly identifying $I30 indexes for as long as I can remember. Figure 2 shows what they look like in FTK. Simply right-click on the $I30 file to export from the image.
The Sleuth Kit (TSK) also does an excellent job with Index Attributes, although the interface takes a little practice. Figure 3 shows output from the TSK istat tool for a RECYCLER child directory. Near the bottom of the output we see the NTFS attribute list.
You may notice multiple attributes using the $I30 name in Figure 3. Brian Carrier's File System Forensic Analysis book dissects each of these attributes, and the simple explanation is they are all components of the overall Index Attribute [1]. To export the $I30 attribute from this directory, we use the icat tool from TSK and give it the MFT entry number of the directory along with the identifier for the $INDEX_ALLOCATION attribute, which in this case is "160-4" (Figure 4). This output is redirected into a file named, $I30.

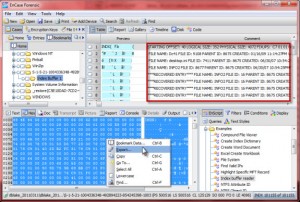
To identify index attributes in EnCase, an EnScript is required. An Enscript ships within the stock Examples folder and is named, "Index buffer reader". This script can be pointed at a specific directory, a collection of tagged directories, or the entire file system. The results are nicely bookmarked and the entries are parsed within each bookmark's comments field. To export the $I30 file in EnCase, you first select the "Index Buffer" that you are interested in within the Tree Pane, select all within the View Pane, and right-click and select Export (Figure 5).
The format of $I30 entries is well known and extensively documented. However, indexes commonly reach sizes in the hundreds of kilobytes and hold thousands of entries (theoretically they could have billions of entries). It is tiresome work to do the parsing by hand. Of the previously covered forensic suites, only EnCase has a native ability to parse the files, though the output is very difficult to use and analyze. Luckily, Willi Ballenthin recently released an open source tool that does an excellent job of parsing $I30 files [2]. It formats output as CSV, XML, or bodyfile (for inclusion into a timeline) and has a feature to search remnant space for slack entries. The tool is written in Python and sample command line follows:
python INDXParse.py -d $I30 > $I30_Parse.csv
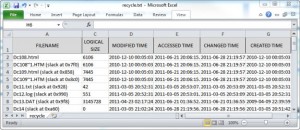
The resulting file can be opened and filtered in Excel (CSV output is the default). Notice the file names, file size, and four timestamps displayed in the output shown in Figure 6. Several deleted index node entries (slack) are also displayed within the output.
[1] File System Forensic Analysis, Brian Carrier (included with the SANS Forensics 508 Course)
[2] INDXParser.py by Willi Ballenthin
[3] John McCash previously discussed Index Attributes
